
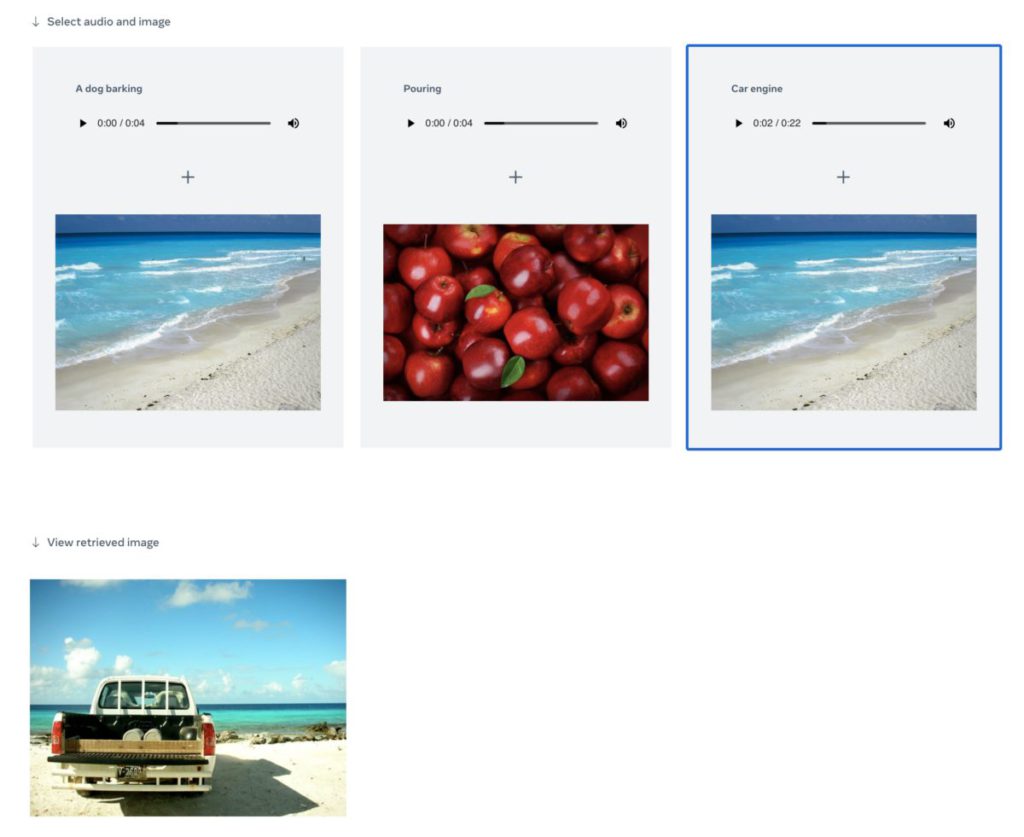
我們這幾個月來一直用到的文字、圖像以至影片生成式 AI,大多是從一種資料生成另一種資料,不過人類的推理結合不同感知能力。Meta 昨日繼 LLaMA、Segment Anything 等模型後,又再開源另一個與 AI 有關的項目 ImageBind,將 6 種模式資料綁定在同一個嵌入空間(Embedding Space),能實現跨模式的新型應用。

ImageBind 為 6 種模式(modality)——文字、聲音、影片及圖像、深度圖、熱力圖和慣性運動(IMU),提供一個單一嵌入空間互相關聯,開發人員不需要對每一種模式組合的資料進行訓練,也可以製作出跨模式的應用。現有的 AI 模型亦可透過 ImageBind 來接受更多種類資料輸入,例如聲音搜尋和跨模式生成等。
例如提供老虎的圖像,可以生成老虎吼叫的聲音,再加上瀑布的聲音的話,可以生成老虎和瀑布旁行過的影片。同時提供流水聲和生果的圖片,可以生成在洗碗盤洗生果的圖像。
Meta 提供了一個示範網站,供大眾了解 ImageBind 的功能。
{kind=link}
在 Meta 最近的業績發表會上,CEO 朱克伯格曾表示 Meta 今後都會同時專注於 AI 和元宇宙,並將兩者結合起來。而 ImageBind 就可以將 3D 感測器和 IMU 慣性感測器結合,實現沉浸式虛擬空間,對發展元宇宙有幫助。